


1.写在前面
DeepSeek无疑是近期科技圈、AI圈最火的大模型之一。今天我们来试试本地化部署DeepSeek大模型,本地化部署的优点是无需联网,且不用上传隐私数据,对于中小型企业来讲,本地化部署更能训练出私有应用的大模型,更适应于多元化的应用场景。
当然缺点也很明显,你需要准备能够运行DeepSeek的硬件,推理的速度和精度也取决于你的硬件性能,另外你的本地版本不会像在线版本那样新。
硬件要求:
CPU:建议至少 4 核(如 Intel i5 或更高)。
GPU(可选):推荐 NVIDIA GPU(如 RTX 3060 或更高),支持 CUDA 加速。
内存:建议 16GB 以上。
存储:至少 20GB 可用空间(用于安装依赖和模型文件)。
软件要求
操作系统:Linux(如 Ubuntu 20.04)或 Windows 10/11。
Python:3.8 或更高版本。
CUDA(如使用 GPU):11.3 或更高版本。
cuDNN(如使用 GPU):与 CUDA 版本匹配。
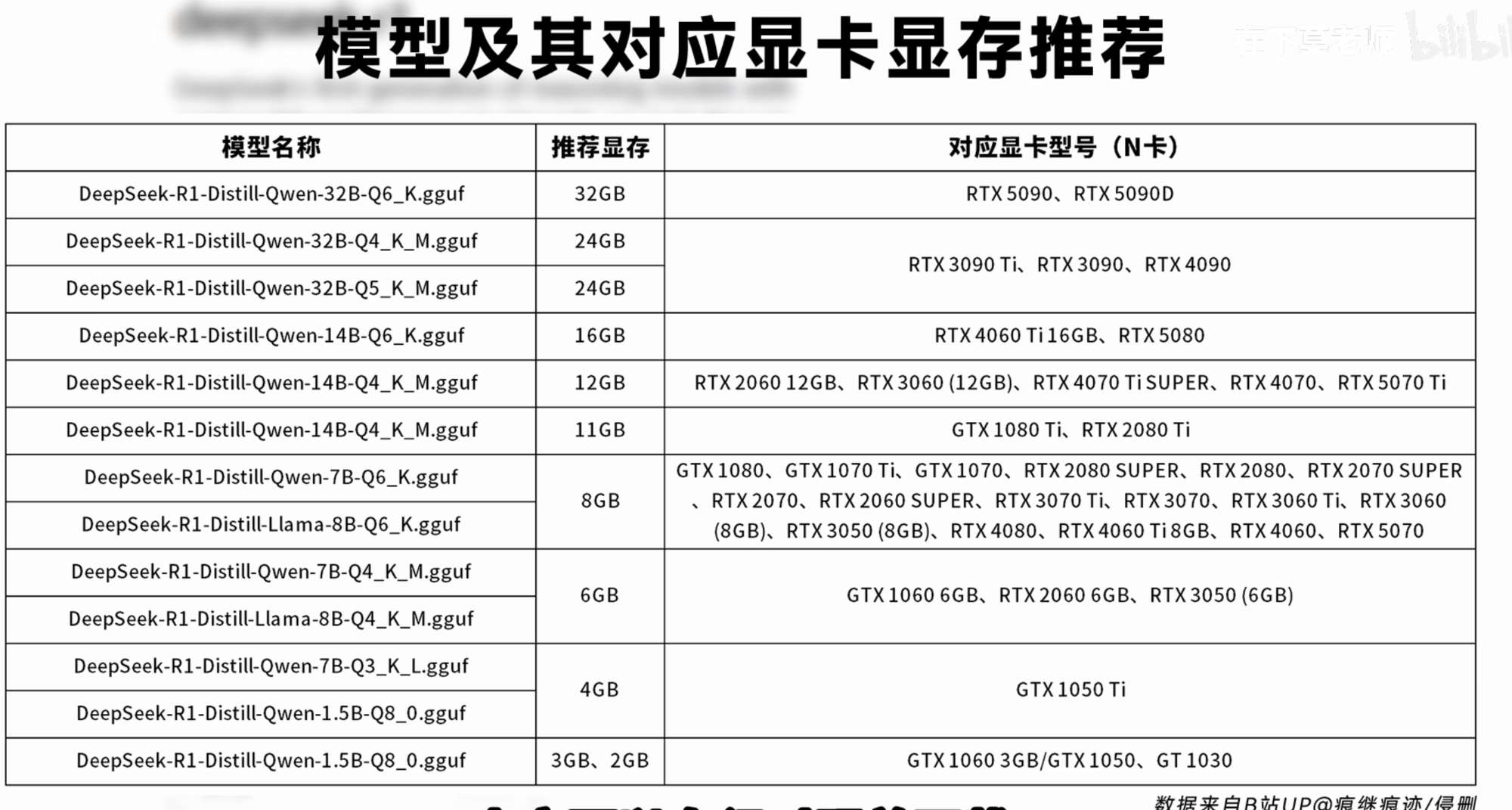
详细的硬件配置要求,可以参看下面这张图:
2.安装Ollama与拉取模型
首先安装Ollama应用。Ollama 是一个开源的大型语言模型本地部署框架,支持 macOS、Windows、Linux 以及 Docker,覆盖了主流操作系统,提供了丰富的模型库,如搜集了大量的开源 LLM 模型,如 llava、gemma、Llama2、Qwen2 等。
访问ollama的官方网站,根据自己的操作系统选择下载安装,安装直接默认即可。
https://ollama.com/download由于我使用的是NVIDIA的RTX 3090显卡。
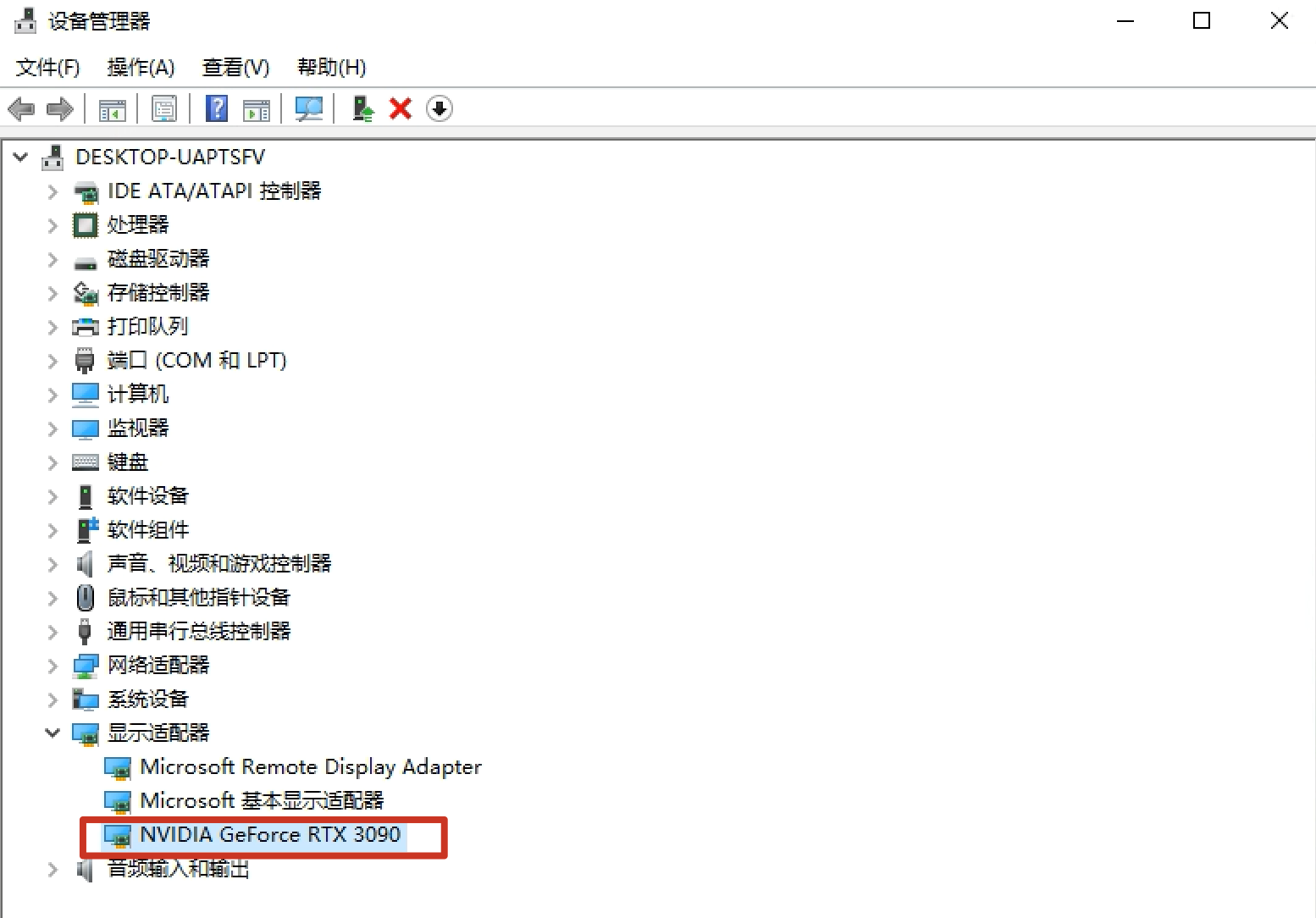
专用显存为24GB,所以根据配置对照表,我这里选择DeepSeek的32b版本模型。
https://ollama.com/library/deepseek-r1:32b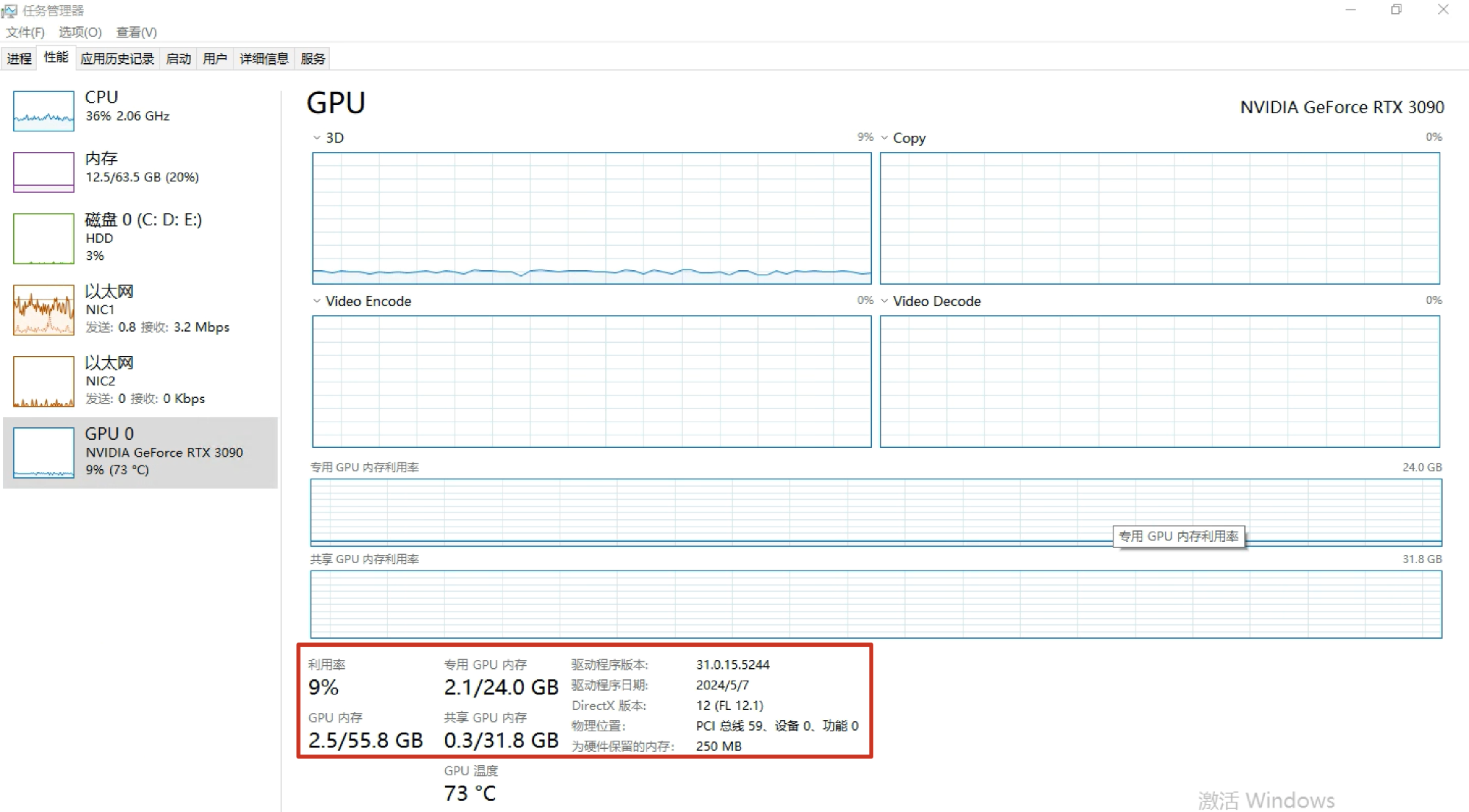
选择32b,然后点击右侧的复制按钮复制代码。
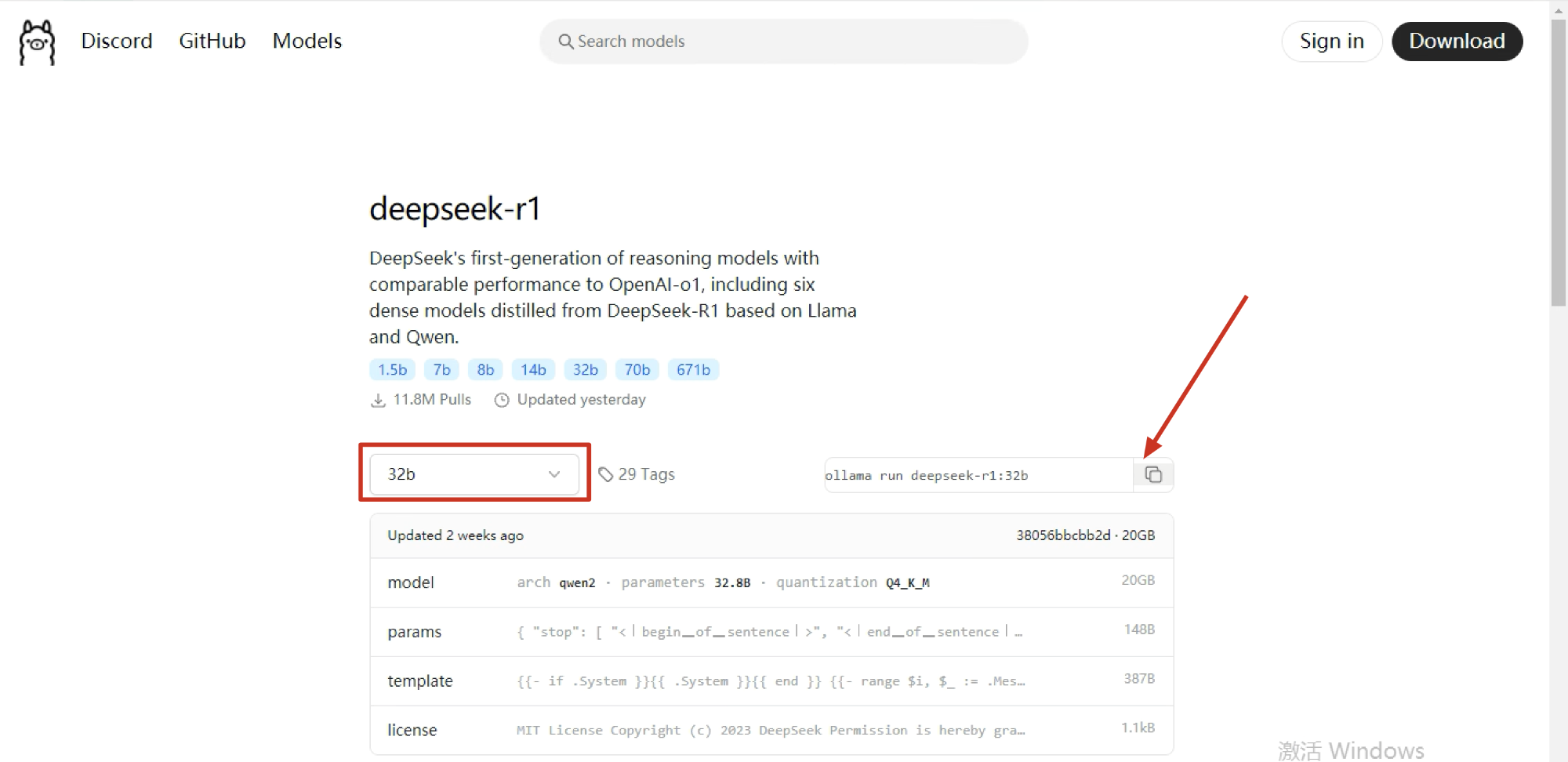
复制后,在CMD命令提示符中执行粘贴并回车执行。如果运行一段时间后没有下载速度,可以使用“Ctrl + C”指令结束掉任务后,再次粘贴下载,默认会断点续传且速度会变快。

出现如图所示的下载进度时,表明模型已经拉取成功。拉取成功后,系统直接运行了模型。

尝试对话:

深度思考时,可以看到GPU占用率在40%左右, 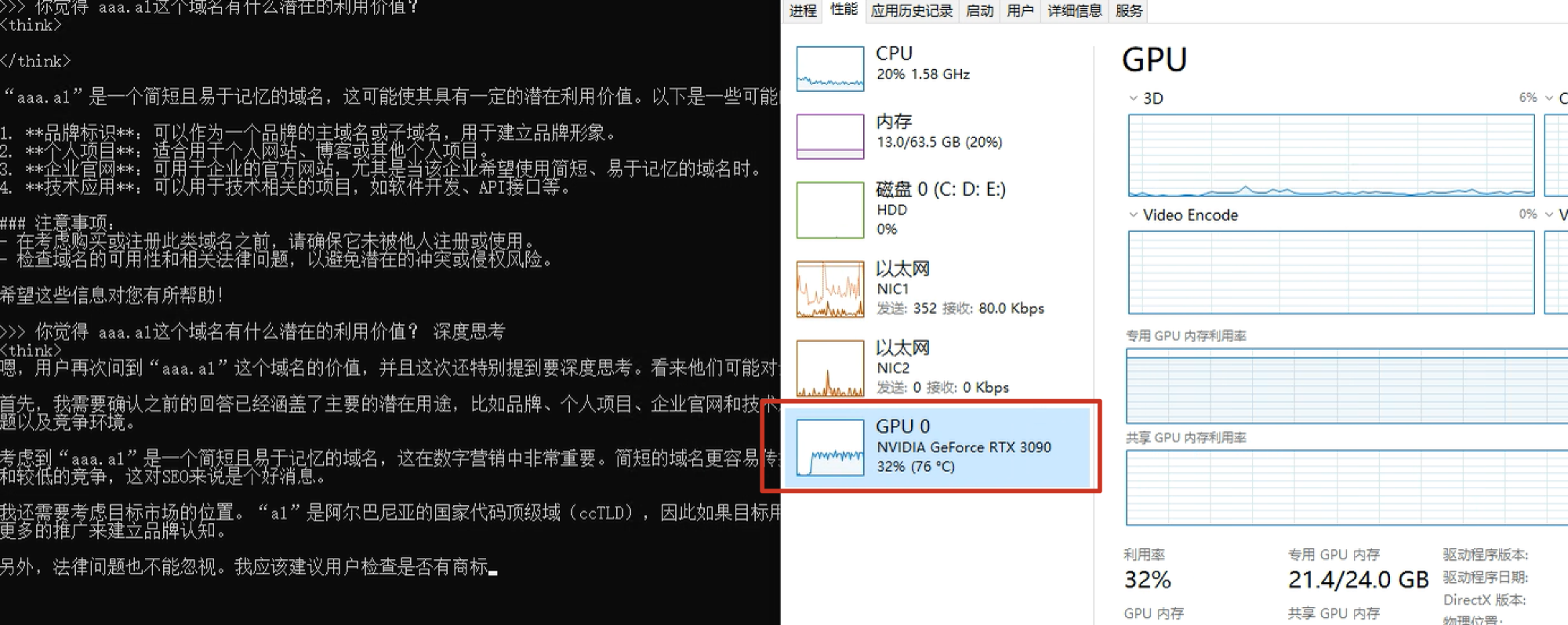
3.重启调用
当我们重启电脑或Ollama应用后,应当如何再次启动我们的模型呢?使用Ollama help可以看到所有的命令提示:
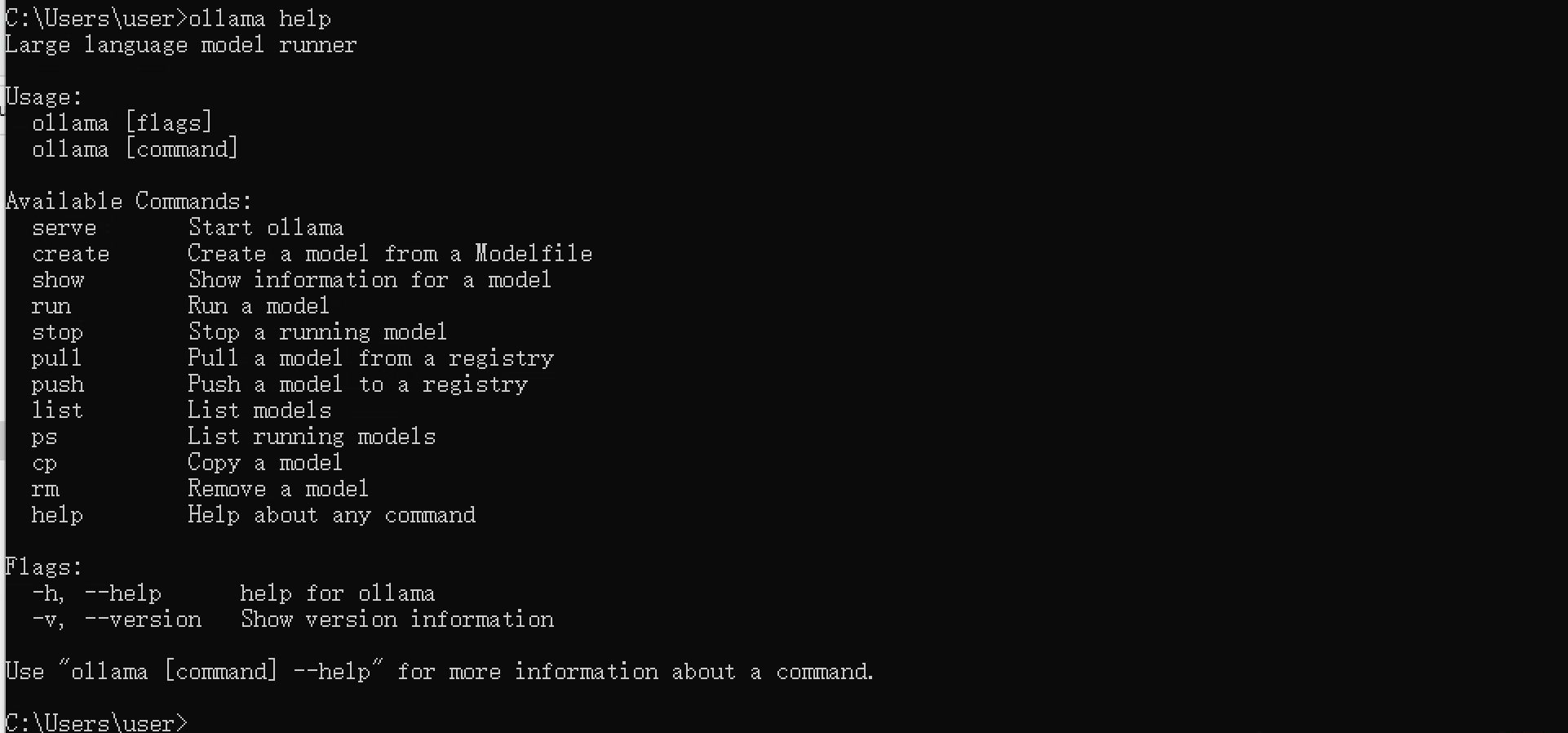
其中ollama list和ollama run命令分别为列出所有模型和运行模型。
ollama list比如我这里只有一个模型,名称为deepseek-r1:32b

运行这个模型:
ollama run deepseek-r1:32b可以看到模型正常运行,可以进行对话了。

下期我们演示如何使用web远程调用的方式使用deepseek。
评论区